
철학과 학생의 개발자 도전기
패스트캠퍼스 환급챌린지 7일차 : 10개 프로젝트로 한 번에 끝내는 MLOps 파이프라인 구현 초격차 패키지 Online. 강의 후기 본문
패스트캠퍼스 환급챌린지 7일차 : 10개 프로젝트로 한 번에 끝내는 MLOps 파이프라인 구현 초격차 패키지 Online. 강의 후기
Younghun 2025. 3. 11. 22:58본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
온라인 강의 7주년 기념 1+1 이벤트 특별 연장! (3/10~3/12) | 패스트캠퍼스
단 3일! 미션, 리뷰, 인증 NO! 강의 사면 무.조.건 1+1 쿠폰 증정🎉
fastcampus.co.kr
수강 인증
수강 후기
안녕하세요. 환급챌린지 7일차 포스팅입니다.
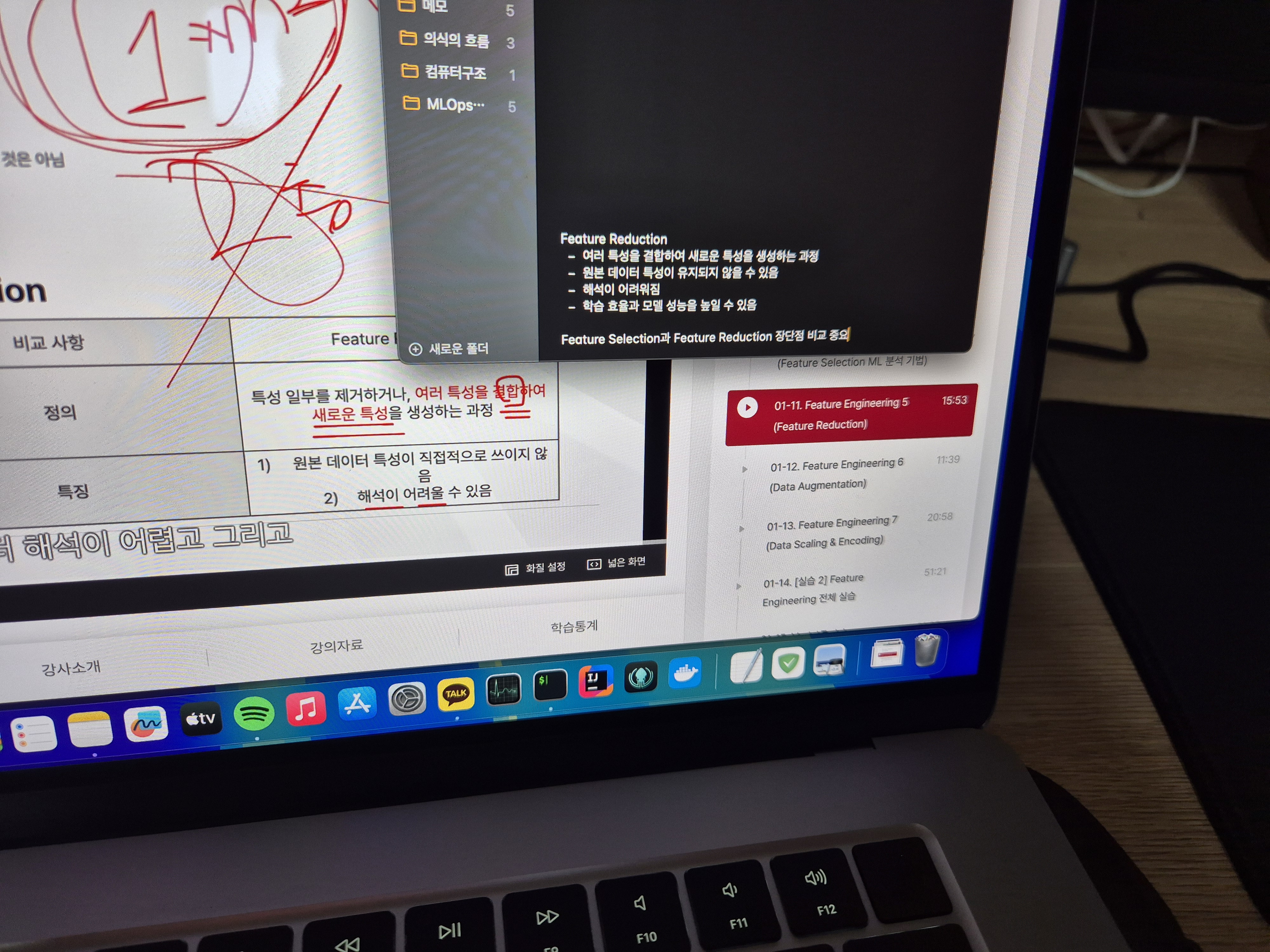
오늘은 머신러닝 모델 개선을 위한 Feature Reduction에 대해 배웠습니다.
어제 배운 Feature Selection과 비슷한 개념이라고 생각했는데, 오늘 강의를 듣고 보니 두 개념이 확연히 다르다는 걸 깨달았습니다. Feature Selection은 불필요한 특성을 완전히 제거하는 방법이라면, Feature Reduction은 기존 특성을 변형하거나 결합하여 더 적은 수의 특성으로 압축하는 방법입니다. 즉, Feature Selection이 "필요 없는 걸 없애는 과정"이라면, Feature Reduction은 "기존 특성을 가공해서 더 효과적으로 만드는 과정"이라고 볼 수 있습니다.
오늘 배운 여러 가지 Feature Reduction 방법 중에서 가장 인상 깊었던 것은 주성분 분석(PCA, Principal Component Analysis)이었습니다. PCA는 원래 데이터의 특성을 선형 변환하여 서로 상관관계가 없는 새로운 특성(주성분)을 만들어내는 방법입니다. 데이터의 분산을 최대한 유지하면서도 차원을 줄일 수 있기 때문에, 데이터 손실을 최소화하면서도 모델을 단순화할 수 있다는 점이 흥미로웠습니다.
이론적으로는 단순해 보이지만, 실제 데이터에 적용해 보면 해석이 쉽지 않은 기법이라는 생각도 들었습니다. 기존 특성들이 변형되면서 직관적인 해석이 어려워질 수 있기 때문입니다. 하지만, 고차원의 복잡한 데이터에서 핵심적인 정보만 뽑아낼 수 있는 강력한 도구라는 점에서 머신러닝 모델을 개선하는 데 유용하게 쓰일 것 같습니다.
Feature Selection과 Feature Reduction을 모두 배우면서 느낀 점은, 좋은 모델을 만들기 위해서는 데이터 자체를 얼마나 잘 이해하고 가공하는지가 핵심이라는 것입니다. 단순히 모델의 복잡도를 높이기보다는, 필요한 정보만 남기고, 효과적으로 변환하여 모델이 학습하기 좋은 환경을 만드는 과정이 중요하다는 걸 다시금 깨달았습니다.
이제 점점 머신러닝 모델을 개선하는 핵심적인 개념들을 배워가고 있는 것 같아 더욱 흥미롭습니다. 다음 강의에서는 이 개념들을 실습해볼 수 있길 기대하며, 오늘의 후기를 마칩니다.



