
철학과 학생의 개발자 도전기
패스트캠퍼스 환급챌린지 3일차 : 10개 프로젝트로 한 번에 끝내는 MLOps 파이프라인 구현 초격차 패키지 Online. 강의 후기 본문
패스트캠퍼스 환급챌린지 3일차 : 10개 프로젝트로 한 번에 끝내는 MLOps 파이프라인 구현 초격차 패키지 Online. 강의 후기
Younghun 2025. 3. 7. 23:37본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
봄맞이 특급 혜택 '하나 더 봄'🌸 1+1 이벤트 (3/4~3/9) | 패스트캠퍼스
당신의 성장도 피어날 거예요. 1+1 쿠폰으로 강의 보고 또 보고!
fastcampus.co.kr
수강 인증

수강 후기
안녕하세요. 환급챌린지 3일차 포스팅입니다.
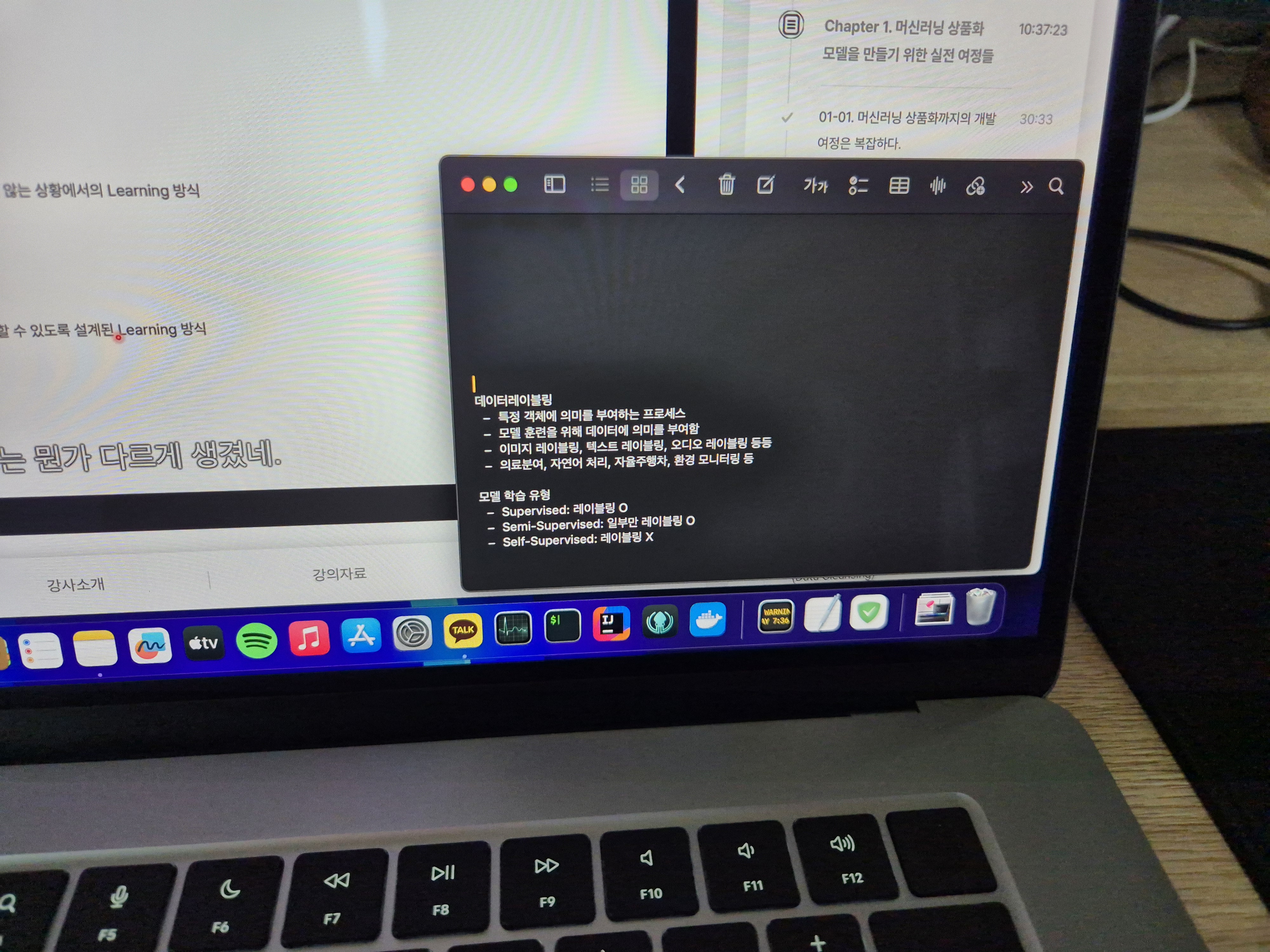
오늘은 데이터 레이블링과 모델 학습 유형에 대해 배웠습니다.
강의가 점점 본격적으로 시작되는만큼 난이도도 어려워지는 것 같습니다. 데이터 레이블링은 데이터에 의미를 부여하는 프로세스입니다. 모델이 원하는 Task를 수행하기 위해 데이터에 적절히 레이블링을 하여 일종의 정답값을 보여주는 것입니다. 이것은 고양이고, 저것은 강아지라고 알려주고 학습시킬 때 모델은 강아지와 고양이를 더욱 정확히 구분할 수 있을 것입니다.
그 후 배운 모델 학습 유형에서는 꽤나 놀랐습니다. 생각보다 모델 학습 유형이 다양했고, 관점에 따라 학습 유형을 다르게 분류할 수 있었습니다. 데이터 레이블링 여부로 Supervised와 Semi-Supervised, Self-Supervised로 분류할 수 있습니다. 스트리밍 데이터로 지속적인 학습을 하는 Online Learning과 전통적인 방식으로 대량의 데이터를 한번에 학습하는 Batch Learning도 있습니다. 저는 그 중에서 데이터 레이블링 없이 학습이 가능한 Self-Supervised에 관심이 갔습니다. 데이터 레이블링이 공수가 굉장히 많이 드는 작업이고 이 과정을 생략할 수 있다면 돈과 시간을 절약할 수 있기 때문입니다.
ChatGPT 같은 LLM 모델들은 본격적인 모델 학습을 하기 전 Masked Language Model로 먼저 구축한다고 합니다. 입력데이터로 문장이 들어오면 그 중 일부 단어를 가린 뒤 예측하도록 모델을 학습하는 것입니다. 이미 완성된 문장이 입력 데이터로 들어오기 때문에 따로 데이터 레이블링을 해줄 필요도 없습니다. 모델 학습을 연습할 때 이런 간단한 모델로 먼저 학습하는 것도 재밌을 것 같습니다. 제가 예시 입력 데이터를 만들어 주기도 직관적이라 더 흥미가 갑니다. 이론 강의만 듣다보니 슬슬 파이썬으로 직접 데이터를 전처리 하고 싶어집니다. 실습도 기대가 됩니다.



