
철학과 학생의 개발자 도전기
패스트캠퍼스 환급챌린지 2일차 : 10개 프로젝트로 한 번에 끝내는 MLOps 파이프라인 구현 초격차 패키지 Online. 강의 후기 본문
패스트캠퍼스 환급챌린지 2일차 : 10개 프로젝트로 한 번에 끝내는 MLOps 파이프라인 구현 초격차 패키지 Online. 강의 후기
Younghun 2025. 3. 6. 23:13본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
봄맞이 특급 혜택 '하나 더 봄'🌸 1+1 이벤트 (3/4~3/9) | 패스트캠퍼스
당신의 성장도 피어날 거예요. 1+1 쿠폰으로 강의 보고 또 보고!
fastcampus.co.kr
수강 인증
수강 후기
안녕하세요. 환급챌린지 2일차 포스팅입니다.
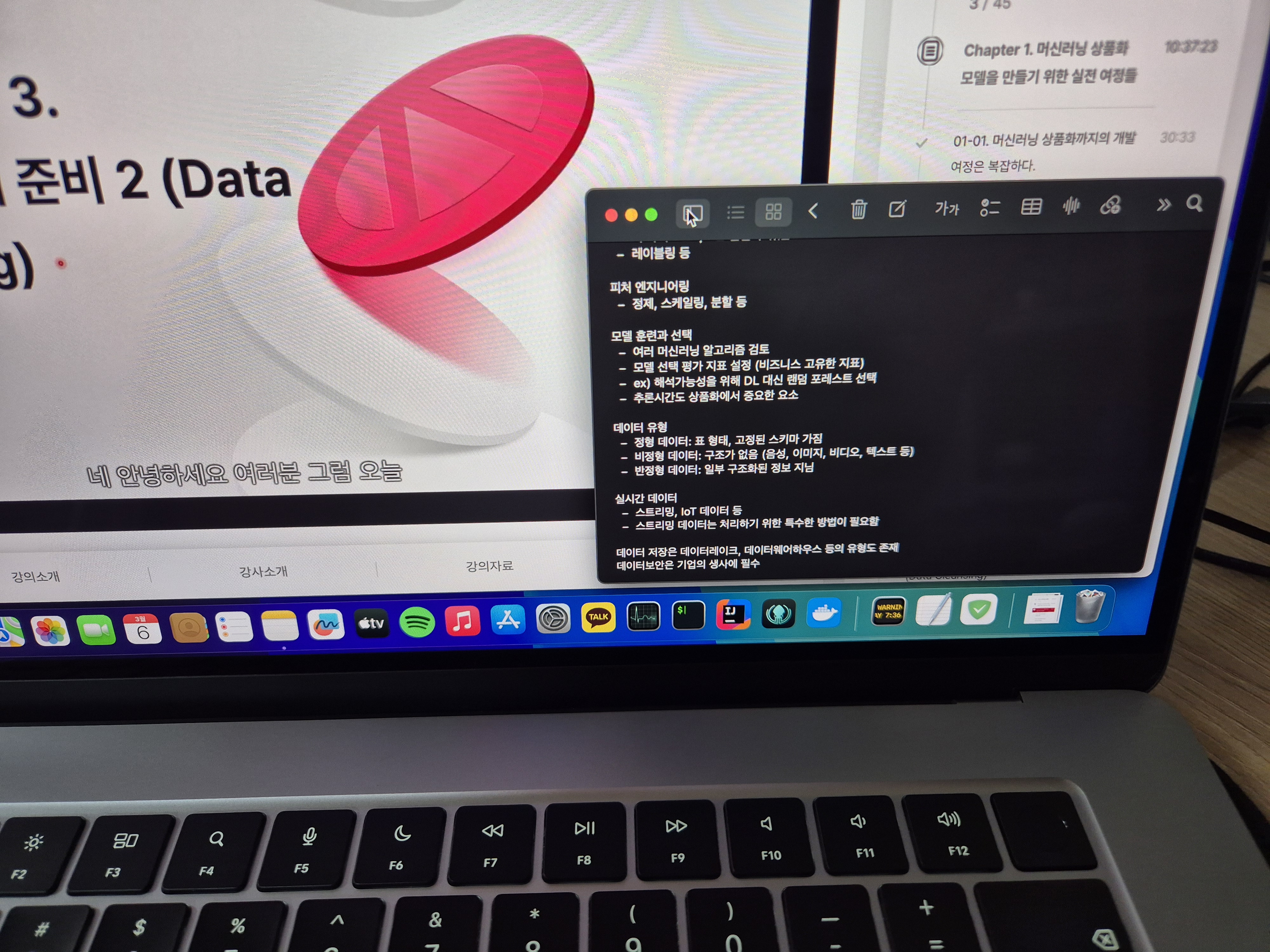
오늘은 학습데이터 준비 과정 중 데이터 유형과 데이터 샘플링에 대해 공부했습니다.
학습데이터를 준비하는 과정은 매우 중요합니다. 양질의 데이터에서 좋은 머신러닝 모델이 만들어지기 때문입니다. 하지만 캐글과 같은 인위적인 대회환경과 달리 현실에서의 데이터 준비는 굉장히 어렵습니다. 데이터 유형에는 정형, 비정형, 반정형 데이터가 있다고 합니다. 저는 주로 정형데이터를 다뤘습니다. 스키마가 존재하는 RDB에 저장된 데이터가 그 예입니다. 이러한 데이터는 강력하게 구조화되어있기 때문에 분석하기도 사용하기도 편합니다. 하지만 비정형 데이터는 어떨까요? 사람의 음성 데이터, 비디오 영상 데이터, 대화 텍스트 데이터 등은 구조화가 굉장히 어렵습니다. 정해진 스키마로 자르기 어렵기 때문입니다. 머신러닝은 이러한 데이터를 다룰 일도 많습니다.
저는 비정형 데이터에 관심이 생겼습니다. 특히 비디오, 스트리밍 데이터를 특수한 기법으로 처리한다는 강의 내용을 듣고 관심이 더욱 커졌습니다. 앞으로 비디오 데이터의 중요성은 더욱 커지는 만큼 시장의 기술 수요도 높아질 것으로 예상되기 때문입니다. 인터넷 방송을 종종 보는 입장에서 실시간 스트리밍 데이터를 처리하는 MLOps도 재밌을 것 같다고 생각했습니다. 확실히 다양한 분야의 지식을 좋은 강의로 수강하며 듣다보니 관심의 폭이 넓어지고 이전에는 생각지도 못한 진로를 생각하게 되는 것 같습니다. 좋은 영향입니다.
데이터 샘플링도 전문성을 키우기 좋은 영역같습니다. 100테라바이트의 데이터 전체를 학습시키는 것보다 1테라바이트의 데이터를 학습시키는 것이 당연히 비용이 적을 것입니다. 만약 데이터 샘플링으로 전체 데이터가 아닌 일부 데이터로 학습을 해도 이전과 같은 결과 혹은 더 나은 결과를 보인다면 굉장히 유용한 기술일 것입니다. 이론적으로, 경험적으로 데이터 샘플링 기술을 익혀서 적은 데이터로 높은 효과를 내고 싶습니다. 이것이 엔지니어링의 매력 아닐까요?



