
철학과 학생의 개발자 도전기
패스트캠퍼스 환급챌린지 11일차 : 10개 프로젝트로 한 번에 끝내는 MLOps 파이프라인 구현 초격차 패키지 Online. 강의 후기 본문
패스트캠퍼스 환급챌린지 11일차 : 10개 프로젝트로 한 번에 끝내는 MLOps 파이프라인 구현 초격차 패키지 Online. 강의 후기
Younghun 2025. 3. 15. 16:24본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
커리어 성장을 위한 최고의 실무교육 아카데미 | 패스트캠퍼스
성인 교육 서비스 기업, 패스트캠퍼스는 개인과 조직의 실질적인 '업(業)'의 성장을 돕고자 모든 종류의 교육 콘텐츠 서비스를 제공하는 대한민국 No. 1 교육 서비스 회사입니다.
fastcampus.co.kr
수강 인증

수강 후기
안녕하세요. 환급챌린지 11일차 포스팅입니다.
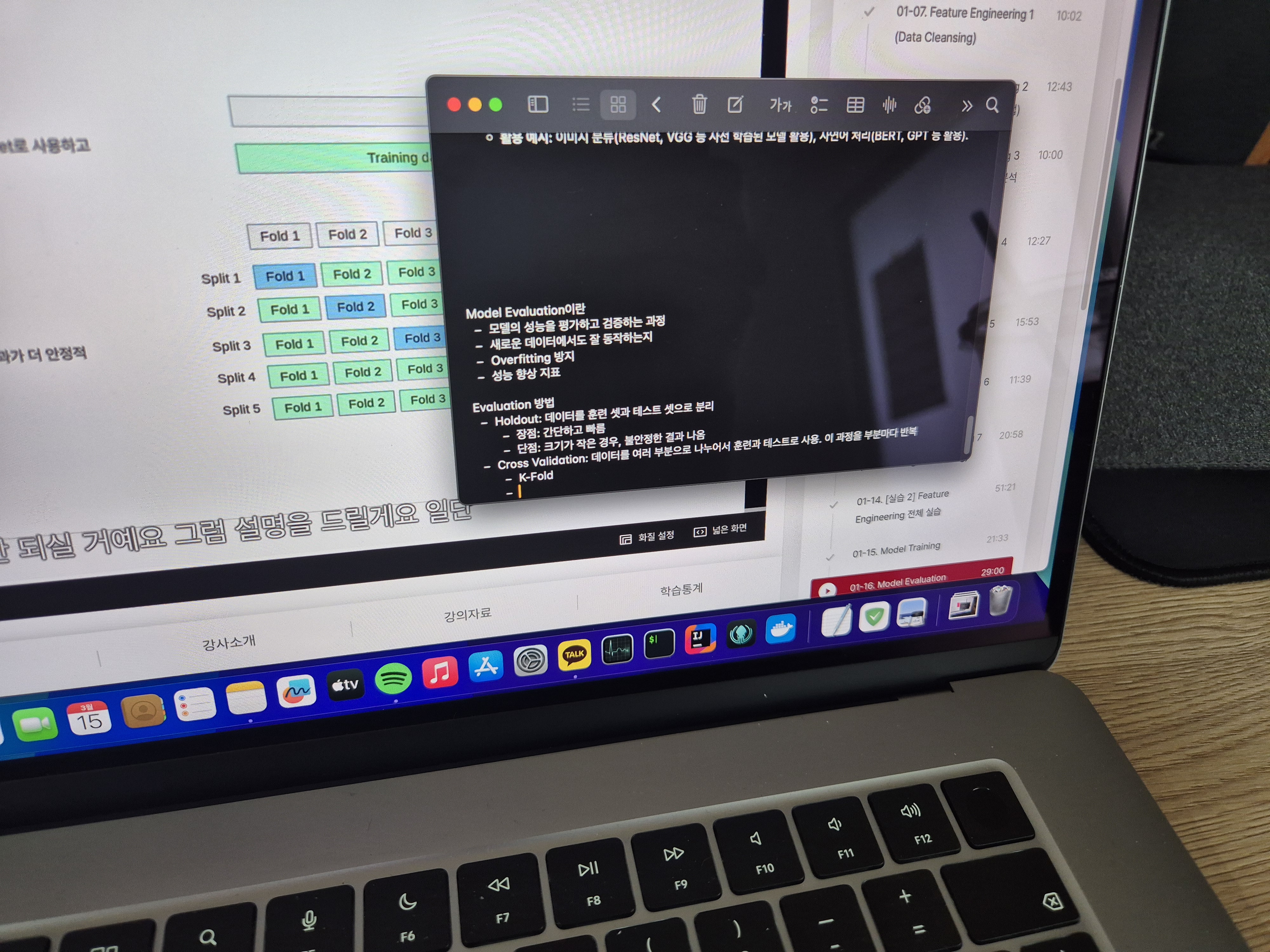
오늘은 Model Evaluation(모델 평가)에 대해 배워봤습니다.
머신러닝 모델을 학습시키는 것만큼 중요한 과정이 바로 모델이 얼마나 성능이 좋은지 객관적으로 평가하는 단계입니다. 모델을 적절하게 평가하지 않으면, 실제 환경에서 제대로 동작하지 않는 모델을 배포하게 될 위험이 있습니다. 오늘 강의에서는 다양한 모델 평가 방법과 각각의 특징을 배울 수 있었습니다.
1. Model Evaluation의 개념
모델 평가는 학습된 모델이 새로운 데이터에서도 일관된 성능을 보이는지 확인하는 과정입니다.
일반적으로 모델을 학습할 때 **훈련 데이터(Train Data)와 테스트 데이터(Test Data)**를 분리하여 평가를 수행합니다.
모델이 훈련 데이터에서는 좋은 성능을 보이지만, 테스트 데이터에서 성능이 낮다면 과적합(Overfitting) 문제가 발생한 것으로 볼 수 있습니다.
이를 방지하기 위해 다양한 평가 방법이 활용됩니다.
2. 모델 평가 방법
오늘 강의에서는 모델 평가를 위한 주요 방법들을 배웠습니다.
1) Hold-out Validation (홀드아웃 검증)
- 데이터를 훈련(train) / 검증(validation) / 테스트(test) 세 개의 세트로 분할하여 평가하는 방식입니다.
- 가장 간단한 방법이지만, 데이터의 분할 방식에 따라 결과가 달라질 수 있다는 단점이 있습니다.
- 일반적으로 Train:Validation:Test = 70:15:15 또는 80:10:10 비율로 사용됩니다.
2) K-Fold Cross Validation (K-폴드 교차 검증)
- 데이터를 K개의 폴드(Fold)로 나눈 후, 한 폴드를 검증 데이터로 사용하고 나머지를 훈련 데이터로 사용하는 방식입니다.
- 이 과정을 K번 반복하여 평균 성능을 측정하므로, 데이터 분할의 편향을 줄이고 보다 신뢰할 수 있는 평가를 수행할 수 있습니다.
- K 값은 보통 5 또는 10을 많이 사용합니다.
3) Leave-One-Out Cross Validation (LOO-CV)
- K-Fold와 유사하지만, 하나의 데이터를 검증 데이터로 사용하고 나머지를 훈련하는 방식입니다.
- 데이터가 적을 때 유용하지만, 연산 비용이 매우 크다는 단점이 있습니다.
4) Stratified K-Fold
- K-Fold와 동일한 방식이지만, 클래스 불균형이 있는 데이터에서도 균형을 유지할 수 있도록 폴드를 나누는 방식입니다.
- 분류(Classification) 문제에서 특히 효과적입니다.
5) Time Series Split (시계열 데이터 평가)
- 시계열 데이터에서는 데이터가 시간 순서대로 정렬되어 있기 때문에 일반적인 K-Fold 검증이 적절하지 않습니다.
- 과거 데이터를 학습하고 미래 데이터를 검증하는 방식으로 평가를 수행합니다.
3. 모델 성능 평가 지표
단순히 모델을 검증하는 것뿐만 아니라, 어떤 기준으로 모델을 평가할 것인지도 중요합니다.
오늘 강의에서는 여러 가지 평가 지표를 배웠는데, 대표적인 지표는 다음과 같습니다.
1) 회귀 모델 평가 지표
- MSE (Mean Squared Error, 평균 제곱 오차): 오차를 제곱하여 평균을 낸 값으로, 값이 작을수록 성능이 좋음.
- RMSE (Root Mean Squared Error, 평균 제곱근 오차): MSE의 제곱근 값으로, 원래 단위와 동일하여 해석이 용이함.
- MAE (Mean Absolute Error, 평균 절대 오차): 절대값을 취한 오차의 평균으로, 이상치(outlier)에 덜 민감함.
- R² (결정계수): 모델이 데이터를 얼마나 잘 설명하는지 나타내는 지표로, 1에 가까울수록 좋음.
2) 분류 모델 평가 지표
- 정확도(Accuracy): 전체 샘플 중 정답을 맞힌 비율. 데이터가 불균형할 경우 적절하지 않을 수 있음.
- 정밀도(Precision): 모델이 양성(Positive)이라고 예측한 샘플 중 실제로 양성인 비율.
- 재현율(Recall, Sensitivity): 실제 양성 샘플 중 모델이 양성이라고 예측한 비율.
- F1-Score: 정밀도와 재현율의 조화 평균으로, 두 지표의 균형을 평가함.
- ROC-AUC (Receiver Operating Characteristic - Area Under Curve): 모델의 전체적인 성능을 나타내는 지표로, 1에 가까울수록 좋음.
4. 오늘 강의를 통해 얻은 인사이트
오늘 강의를 들으면서 모델을 평가하는 과정이 단순한 테스트가 아니라, 최적의 모델을 찾고 일반화 성능을 높이는 중요한 과정이라는 것을 다시 한번 깨달았습니다.
특히, 데이터의 특성에 따라 적절한 평가 방법과 지표를 선택하는 것이 중요하다는 점이 인상적이었습니다.
✔ 데이터가 충분히 크다면? → K-Fold Cross Validation 활용
✔ 데이터가 적다면? → Leave-One-Out Cross Validation 고려
✔ 클래스 불균형이 심하다면? → Stratified K-Fold 활용
✔ 시계열 데이터라면? → Time Series Split 활용
또한, 정확도(Accuracy) 하나만 보고 모델을 평가하는 것은 위험할 수 있으며, Precision, Recall, F1-score 같은 다양한 지표를 함께 고려해야 한다는 점도 중요하게 느껴졌습니다.
이제 모델을 평가하는 다양한 방법을 익혔으니, 앞으로는 실습을 통해 직접 모델을 비교하고 분석하는 과정에서 이러한 개념들을 적용해 보고 싶습니다.
다음 강의에서는 모델 최적화와 성능 개선 방법에 대해 더 깊이 배울 것 같아 기대됩니다.



